How Noom’s Engineering Team Prepares for the Holidays
By Viktor Braut, Staff Engineer
When your business is helping people lose weight, there is no time like the holidays. After spending a few days indulging in the festivities with their extended family, many people are ready to turn a leaf and look after their health—which means that, at a time when everybody wants to wind down and relax, things tend to get especially busy chez Noom.
I’m sure you’ve all heard about “New Year’s resolutions,” but it turns out that people don’t really wait until the big ball has finished dropping in Times Square to make changes in their lives. Our traffic patterns show that users start thinking about their health right after Christmas Day; some years, traffic to our systems grows by two-digit multiples between December 25th and 26th.
For our Engineering team, this means that we do not enjoy much of a ramp-up on the way to higher levels of scale. We walk right up to a cliff, and then we had better be ready to jump or spend the next month putting out fires and letting down our users and colleagues (not to mention our investors).
As you can imagine, we work hard to avoid the nightmare scenario—not just out of professional pride, but also because we, too, want to enjoy our holidays. Plus, if we are busy dealing with server crashes, we can’t help others deal with the surge of new business. If we plan properly, we can let our systems run more or less on automatic throughout the holidays, but the Coaching team, whose members deal with the new users in real-time, can’t. We want to be ready to assist them with any tooling or functionality they need.
Luck Favours the Prepared
Preparations for the holiday madness usually start around the end of October as part of our planning process for Q4 (our quarters are staggered by a month from the calendar, so the new quarter starts in November). The executive team sets objectives in terms of new user growth and customer satisfaction based on our overall goals for the year. Then we kick off a tiger team made up of representatives from all the major departments involved, like Finance, Marketing, Product, and Engineering, to figure out how to take us where we want to go.
The tiger team’s first order of business is to build a financial model describing our growth curve over the next three months, taking into account behavioural patterns from previous years, projected marketing investment, and many other factors. This model, which lives in a giant Excel spreadsheet, gets a little more sophisticated every year. It outputs a day-by-day breakdown of expected new user acquisition to an almost eerie level of accuracy (at least to an engineer who is used to the “let’s just double it and add 25%” kind of forecasting).

We feed this output into a separate model (written in Python, because Engineering maintains it, and we don’t know how to use Excel), which breaks it down further into a minute-by-minute breakdown of traffic patterns based on factors like access patterns, the timing of specific marketing campaigns, and visitor-to-user conversion rates. This level of detail may seem a little silly, but we need it to determine the peaks and valleys of scale that we need to support. Knowing that you’ll get, say, 50,000 new users in one day isn’t much help for capacity planning if you don’t also know whether they will be spread evenly or lumped in a few critical minutes.
This model, too, improves with age; now that we have a few years’ worth of data on which we can base our predictions, we can usually come to within ±10 percent of real-world behaviour, even during our busiest periods. This is critical because the jump in scale is such that, otherwise, we’d either waste a lot of money in unused infrastructure or risk outages right as our marketing machine is busiest introducing new users to our product.
Bulls and Bears in the Feature Market
Meanwhile, Product and Engineering work together to figure out what new features we can release before we press pause on new development work.
Typically, we work backward from December 26th by about ten days to account for QA and submission to the various app stores and come up with an official code freeze day by which we want to have all new features ready, tested, and out to our users in time for the holidays.
As you can imagine, this makes the remaining time before that date very precious, and there is always a bit of tension between playing it safe and trying to fit one more feature in the development schedule. The process isn’t contentious, because everyone in both teams wants our users to get the latest and greatest functionality we have to offer. However, we occasionally have to remind ourselves that stability is just as important as progress, and be careful that we only push to production functionality in which we have a high degree of confidence.
Not every team is affected by the code freeze, and so some of them continue to tweak things right up until December 24th. Our data infrastructure, for example, tends to work overtime both before (when populating our forecasting models) and during the holidays (when it powers our various AI and ML systems). Our Data Platform and Data Product teams keep plugging away at their work until the very last minute!
Dress Rehearsals Make for a Perfect Show
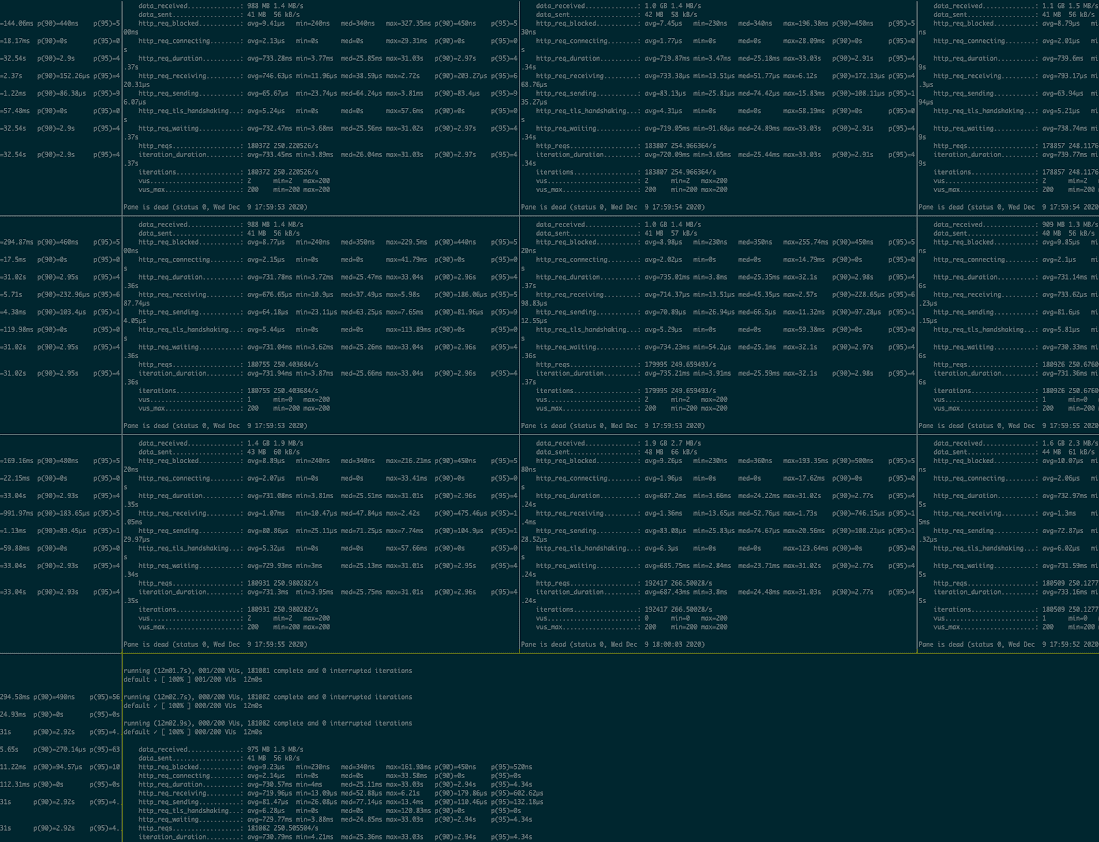
Back in the world of scalability, our Infrastructure team spends most of November building simulated load tests for all of our user-facing systems.
Throughout the rest of the year, when our growth follows a gentler curve, we typically operate at 50% capacity, with the ability to scale 10x from peak with a few hours’ warning. This keeps costs at bay while accounting for the ebb and flow of normal traffic patterns, and, with a little notice, allows us to do some cool things—like, say, putting in a last-minute bid for a TV commercial during the World Series—without too much trouble.
During peak season, this kind of elasticity is no longer appropriate. Knowing we are already likely to face a very significant increase in traffic, adding a 10x buffer on top would require making drastic changes to our architecture that would most definitely result in new instability without any real benefit. Instead, we use our model to determine the kind of traffic patterns that we are going to experience, simulate them, and then see how far we can push our infrastructure beyond our predictions to give ourselves a comfortable cushion in case we’ve underestimated reality.
Like our models, our load tests become increasingly sophisticated every year. What started as a simple set of HTTP requests has now turned into a set of tools that simulate real users’ behaviour as they navigate our purchase process and use their mobile devices. We can now create different synthetic bots, each with their own behaviour and personality, and unleash them in various combinations on our systems to test how they behave at all kinds of scale. They browse, subscribe, purchase add-ons, and log their meals just like real users do.
Typically, we start by building a test environment that closely mirrors production. Because all of our infrastructure is scripted as code, this is relatively easy to do (although it does get more expensive every year!). Next, we simulate a level of traffic similar to what we are currently experiencing to make sure there are no mistakes and that the test environment behaves the same way as its production counterpart.
Then, the fun begins. First, we scale the tests up to expected peak traffic and watch closely for signs of stress in the infrastructure. We fix anything that breaks, and then iterate until everything runs smoothly—at which point we crank everything up as high as it will go and try to figure out where the breaking point is. If we feel the resulting scale is too close to our model for comfort, we make adjustments to allow for a larger buffer until we reach a point where we are no longer worried that our systems will not be able to handle the load.
As you can imagine, this process can, on occasion, get a little stressful. Last year, we spent weeks chasing a problem that eluded us right up until the last minute. It turned out to be a configuration issue causing one of our PostgreSQL databases to become overwhelmed by short-lived connections, but it took a lot of time and effort to figure it out.

Most of the time, though, load testing is also a lot of fun! We get to spin up massive amounts of servers and hammer the living daylights out of them. It’s not hard to find a certain amount of satisfaction in seeing code you’ve worked on scale and scale and scale just by throwing more hardware at it.
Monitor, Monitor on the Wall…
With all the prep work out of the way, our goal in Engineering is to make December 26 and every day after notable only for their mundanity. If we do our jobs well, they’re all just another day at the office, exciting precisely because nothing exciting is happening.
For (I hope) obvious reasons, however, we don’t just leave things to chance. Even the best-laid strategy rarely survives first contact with the user, so we arm ourselves with a variety of tools that help us deal with the unpredictable.
Our first line of defence is a large number of monitors that we have put in place over the years. Every time we learn about a new way our infrastructure can misbehave at runtime, we make sure to have a system in place that alerts us when it happens. After all, the fact that we fixed a problem two years ago doesn’t mean it won’t try to rear its ugly head again—and you can rest assured that, if it does, it will choose the worst possible moment to do so.
Our monitors are set up to work like smoke alarms. We don’t want them to notify us when something has gone bad; by then, it’s already too late to prevent a fire, and that means that, inevitably, someone has to be up in the middle of the night to extinguish it. Thus, over time we have learned to add alarms that use techniques like anomaly detection to tell us when things are about to go sideways, giving us a better chance to anticipate actual problems and address them at a more leisurely pace.
The second line of defence is a really good on-call rotation schedule. At the beginning of our planning process, we ask every engineer to mark their time-off requests for the critical period in a tracking sheet as soon as possible so we can ensure at least one person from every team is always available. Then we do a dry run of our on-call notification system to ensure that things work the way they are supposed to. By design, the on-call rotation is set up so that our executives get notified first; knowing that they will be the first to get a call in the middle of the night is a great way to motivate our VPs to take scalability and stability prep seriously!
Our final—and surprisingly useful—trick is a spreadsheet with a list of contacts at each of our critical vendors. An unexpected byproduct of our scale is that it’s easier for us to request a direct contact from all the providers whose services have the potential to affect our uptime. Being able to cut through a bunch of support layers to get right to the person who can help us address an urgent problem has saved us from trouble more than once.
The Most Wonderful Time of the Year
There is something truly magical about being able to watch our systems pick up massive amounts of traffic at the drop of a hat without us having to keep things from falling over continuously. It makes all of the prep work worth it.
Having a fire-free holiday means we get to dial down the stress and spend a lot of time with our families—always a bonus this time of the year. It also means we can turn our focus inwards and help everyone else deal with rush season, lending an extra hand right when things get busiest.
If you are interested in Noom and want to join our growing engineering team, feel free to reach out to me directly or check our job openings.
